Golang 性能分析神器 pprof 详解与实践(图文教程)
一、简介
pprof(性能剖析工具)是 Go 语言标准库提供的用于 go 程序性能分析的工具。可以帮助你分析程序在 CPU使用率、内存堆栈分配、内存占用、协程、锁等方面的表现并且生成相应的性能分析报告。零侵入性,无需修改服务代码,导入即可生效,生产级安全,采样开销极低,并且具有可视化界面帮助开发者快速定位问题
二、用法
(一)开启 pprof
首先,导入包
import (
_ "net/http/pprof"
)然后,开启一个 http 服务方便获取性能数据
go func() {
logs.Info(http.ListenAndServe(":30552", nil))
}()完整参考代码例子
import _ "net/http/pprof"
func StartPprof() {
go func() {
logs.Info(http.ListenAndServe(":30552", nil)) // 表示启动端口为 30552 的 pprof 服务
}()
}
func main(){
....
// 开启 pprof 性能服务
StartPprof()
// 启动自己的程序
err = router.Run(address)
if err != nil {
panic(err)
}
....
}(二)用法一:直接访问
直接访问 pprof 服务提供的接口
# pprof 的入口首页
http://0.0.0.0:30552/debug/pprof/ 
常用的功能界面如下:
http://0.0.0.0:30552/debug/pprof/heap?debug=1 # 内存堆栈分析(哪些函数一直占用内存)
http://0.0.0.0:30552/debug/pprof/allocs?debug=1 # 内存分配分析(哪些函数在分配内存)
http://0.0.0.0:30552/debug/pprof/goroutine?debug=1 # 协程的情况(总览)
http://0.0.0.0:30552/debug/pprof/goroutine?debug=2 # 协程的具体阻塞堆栈情况
http://0.0.0.0:30552/debug/pprof/block?debug=1 # 阻塞分析
http://0.0.0.0:30552/debug/pprof/block?debug=2 # 阻塞分析
http://0.0.0.0:30552/debug/pprof/mutex?debug=1 # 锁分析
http://0.0.0.0:30552/debug/pprof/mutex?debug=2 # 锁分析⚠️:注意加上参数 debug ,否则访问会直接下载文件,debug=2 展示的信息更全
(三)用法二:go tool pprof(推荐)
直接访问展示是纯文本,不是很直观,所以我们可以使用 go tool pprof 工具展示火焰图,更佳直观的排查问题
需要安装渲染工具:graphviz ;才能正常展示火焰图
graphviz 安装步骤请移步文章:开源的图形可视化工具graphviz安装教程
使用方式:
go tool pprof <参数> <pprof 数据>
# eg:开启 8081 服务展示:采样时间为 60s 的 CPU 耗时数据
# go tool pprof -http=0.0.0.0:8081 -seconds=60 http://0.0.0.0:30552/debug/pprof/profile-
<参数>:
-
-http= 指定一个 ip:port ,启动一个web服务来展示,若未指定,则会下载 xxx.pb.gz 文件,并进入【控制台 cmd 模式】
-
-seconds= 指定采样时间,比如 -seconds=60, 表开始采样 60s 的数据,若未指定,则表示进 程启动以来的总数据
-
-
<pprof 数据>:
可以是 pprof 提供的接口,比如 http://0.0.0.0:30552/debug/pprof/profile
也可以是 pprof 数据文件:比如 xxx.pb.gz
pporf 数据文件可以通过:go tool pprof 下载
# 直接访问可以下载
go tool pprof http://0.0.0.0:30552/debug/pprof/profile # CPU 耗时分析
go tool pprof http://0.0.0.0:30552/debug/pprof/heap # 内存堆栈分析(哪些函数一直占用内存)
go tool pprof http://0.0.0.0:30552/debug/pprof/allocs # CPU 耗时分析
go tool pprof http://0.0.0.0:30552/debug/pprof/goroutine # 协程的情况
go tool pprof http://0.0.0.0:30552/debug/pprof/block # 阻塞分析
go tool pprof http://0.0.0.0:30552/debug/pprof/mutex # 锁分析执行后会保存 xxx.pb.gz 文件,同时进入【控制台 cmd 模式】
常见的指标分析命令如下:
go tool pprof -http=0.0.0.0:8081 http://0.0.0.0:30552/debug/pprof/profile # CPU 耗时分析
go tool pprof -http=0.0.0.0:8081 http://0.0.0.0:30552/debug/pprof/heap # 内存堆栈分析(哪些函数一直占用内存)
go tool pprof -http=0.0.0.0:8081 http://0.0.0.0:30552/debug/pprof/allocs # 内存分配分析(哪些函数在分配内存)
http://0.0.0.0:30552/debug/pprof/goroutine?debug=1 # 协程的情况(总览)
http://0.0.0.0:30552/debug/pprof/goroutine?debug=1 # 协程的具体阻塞堆栈情况
http://0.0.0.0:30552/debug/pprof/block?debug=1 # 阻塞分析
http://0.0.0.0:30552/debug/pprof/block?debug=2 # 阻塞分析
http://0.0.0.0:30552/debug/pprof/mutex?debug=1 # 锁分析
http://0.0.0.0:30552/debug/pprof/mutex?debug=2 # 锁分析以上是常见的指标分析命令,后续步骤会对每个命令展示的界面进行详细说明
三、CPU 耗时分析
分析哪些函数耗时比较久
(一)参考命令
go tool pprof -http=0.0.0.0:8081 http://0.0.0.0:30552/debug/pprof/profile # CPU 耗时分析浏览器会自动(手动)打开 0.0.0.0:8081/ui
这里不加 -seconds=,直接查看进程启动以来的 CPU 耗时数据
(二)火焰图分析
火焰图如下:
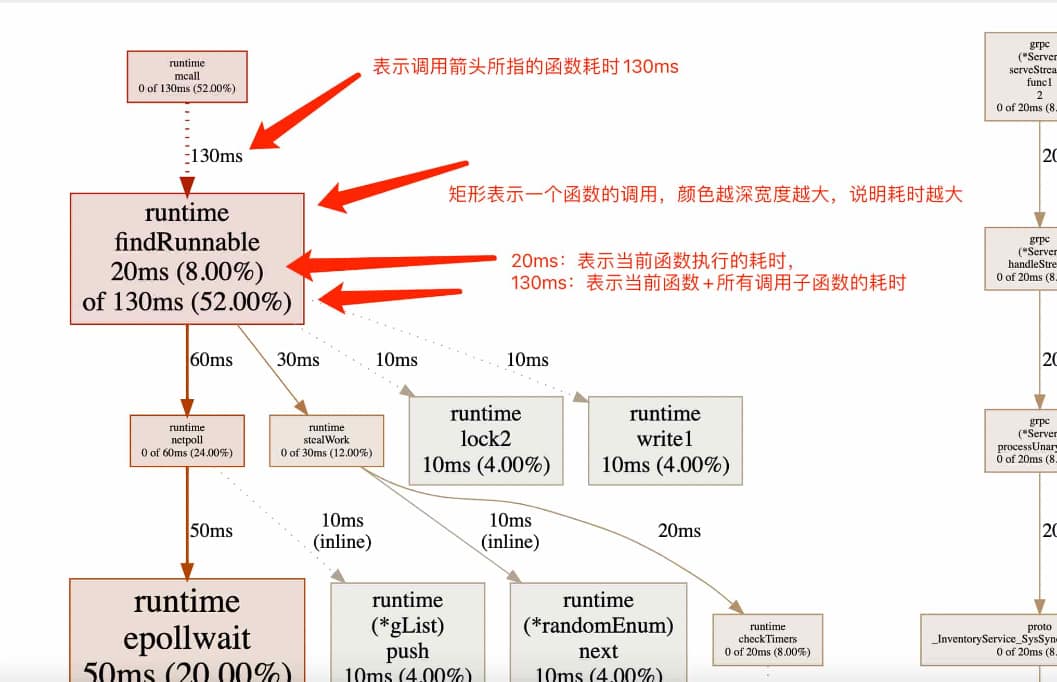
关于图形的说明:
-
框:每个框代表一个函数,理论上框的越大颜色越深表示占用的CPU资源越多。
-
框的颜色:红色表示新增,绿色表示减少,颜色深度表示占用 CPU 资源的多少,比如越红表示 CPU 占用越多
-
框的粗细:和颜色一样,越粗,表示占用 CPU 资源的多少,比如又红又粗,则表示 CPU 占用越多
-
箭头:常见几种如下表
示例 含义 普通调用箭头 FuncA ──→ FuncB显示函数直接调用关系 带资源分配标签的箭头 FuncA ── 50ms → FuncBFuncA 调用 FuncB 的过程中耗时 50ms 虚箭头/虚线箭头 FuncA ···→ runtime.mallocgc编译器隐式插入的耗时操作 双向箭头 FuncA <──> FuncB 相互调用,循环调用,这种可能存在潜在风险 -
(inline):表示该函数在编译时被**内联优化 (Inlining)**处理了
-
框中数字的含义:

函数耗时分析

(三)指标分析
访问 0.0.0.0:8081/ui/top
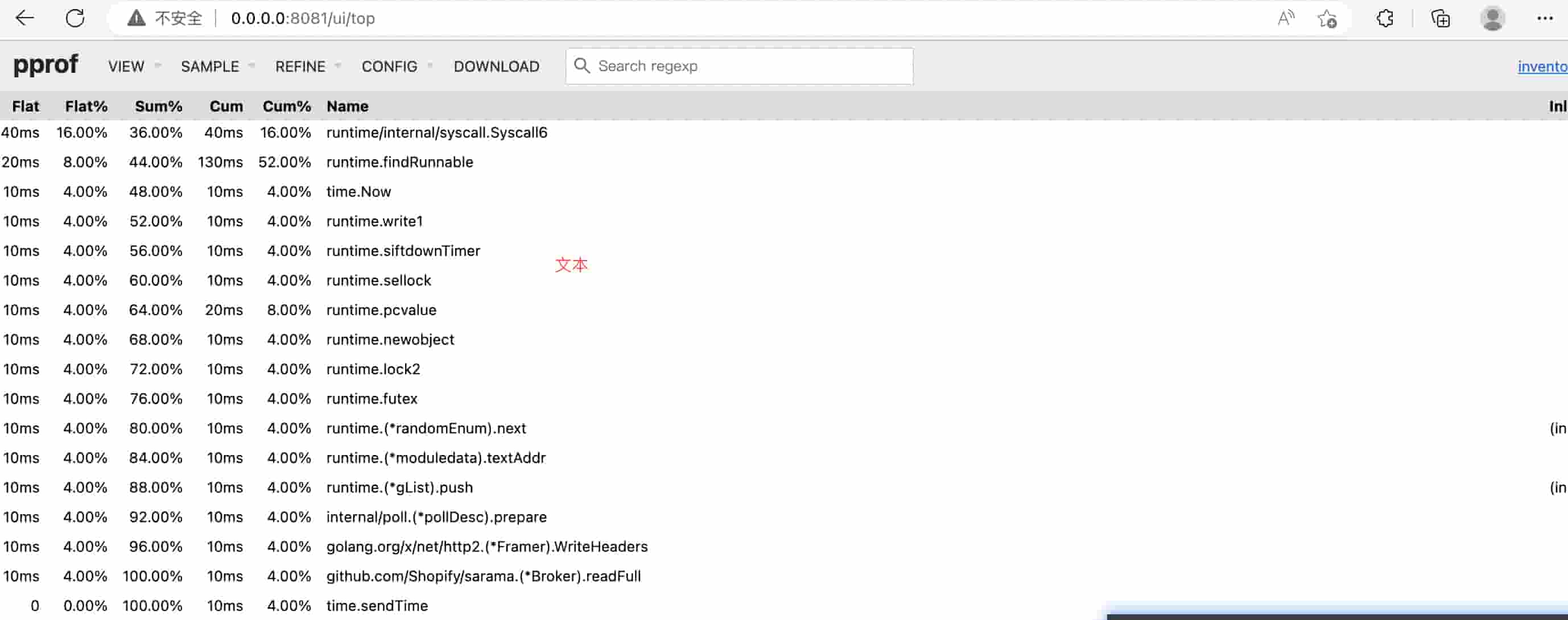
结果和火焰图是一致的,只是展示方式不一样
指标说明:
- flat:指定函数直接执行的时间,即不考虑它调用的任何其他函数的时间。以ms毫秒为单位进行测量。
- flat%:(函数直接执行时间)/ (总执行时间),即 flat / sum * 100。
- sum%:(函数总执行时间)/ (总执行时间),即(flat + 子函数执行时间)/ sum * 100。
- cum:函数总的执行时间,即包括它调用的所有子函数的执行时间。以ms毫秒为单位进行测量。
- cum%:(函数总的执行时间)/ 总执行时间,即(cumulative time for function)/ sum * 100。
(三)总结
-
查看火焰图:
哪个框又红又粗,就是耗时最多的函数,通过函数之间的调用链(箭头)快速定位到函数所在的代码, 然后进行优化(见文末【常见优化措施】)
-
查看
top视图:若火焰图不太能定位函数代码实际位置,可以查看 top 视图,会展示问题函数所在的代码文件
四、内存堆栈分析
分析哪些函数一直在占用内存(常驻内存)
(一)命令
go tool pprof -http=0.0.0.0:8081 http://0.0.0.0:30552/debug/pprof/heap浏览器会自动(手动)打开 0.0.0.0:8081/ui
这里不加 -seconds=,直接查看进程启动以来的内存堆栈数据
(二)火焰图分析
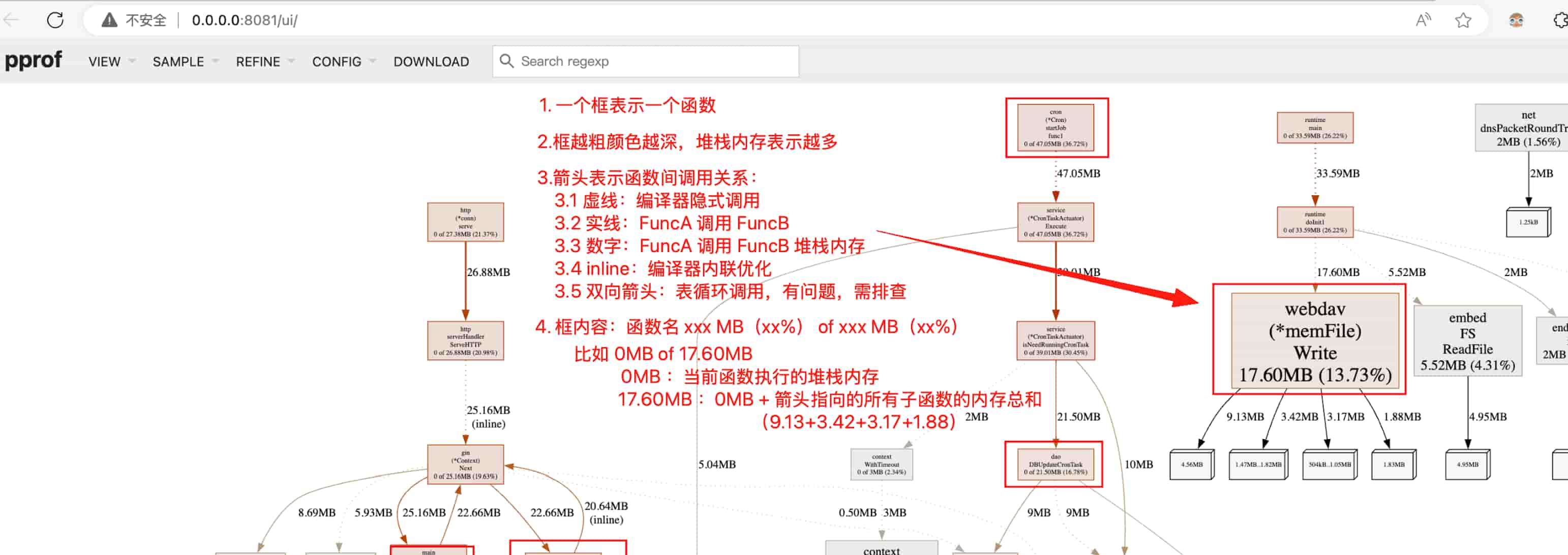
(三)指标分析
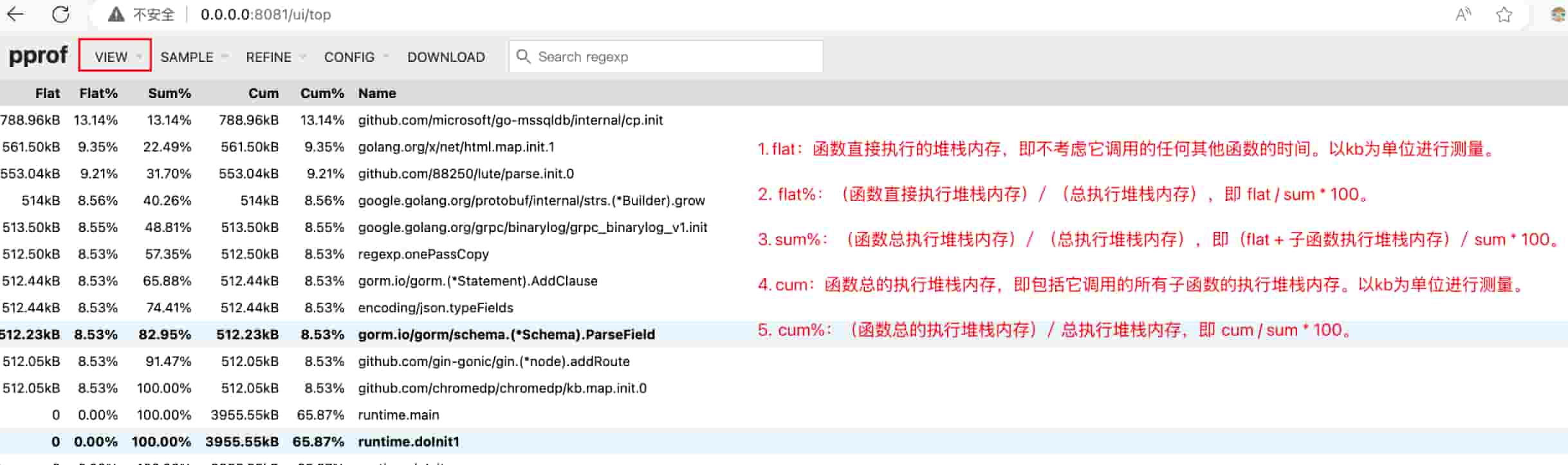
该图为样例图,和上面的火焰图不是同一个采样数据,因此数据是对不上的
- flat:函数直接执行的堆栈内存,即不考虑它调用的任何其他函数的时间。以kb为单位进行测量。
- flat%:(函数直接执行堆栈内存)/ (总执行堆栈内存),即 flat / sum * 100。
- sum%:(函数总执行堆栈内存)/ (总执行堆栈内存),即(flat + 子函数执行堆栈内存)/ sum * 100。
- cum:函数总的执行堆栈内存,即包括它调用的所有子函数的执行堆栈内存。以kb为单位进行测量。
- cum%:(函数总的执行堆栈内存)/ 总执行堆栈内存,即 cum / sum * 100。
(三)总结
-
查看火焰图:
哪个框又红又粗,就是堆栈内存(常驻)最多的函数,通过函数之间的调用链(箭头)快速定位到函数所在的代码, 然后进行优化(见文末【常见优化措施】)
-
查看
top视图:若火焰图不太能定位函数代码实际位置,可以查看 top 视图,会展示问题函数所在的代码文件
五、内存分配分析
分析哪些函数在分配内存
(一)命令
go tool pprof -http=0.0.0.0:8081 http://0.0.0.0:30552/debug/pprof/allocs浏览器会自动(手动)打开 0.0.0.0:8081/ui
这里不加 -seconds=,直接查看进程启动以来的内存分配数据
(二)火焰图分析
火焰图如下:
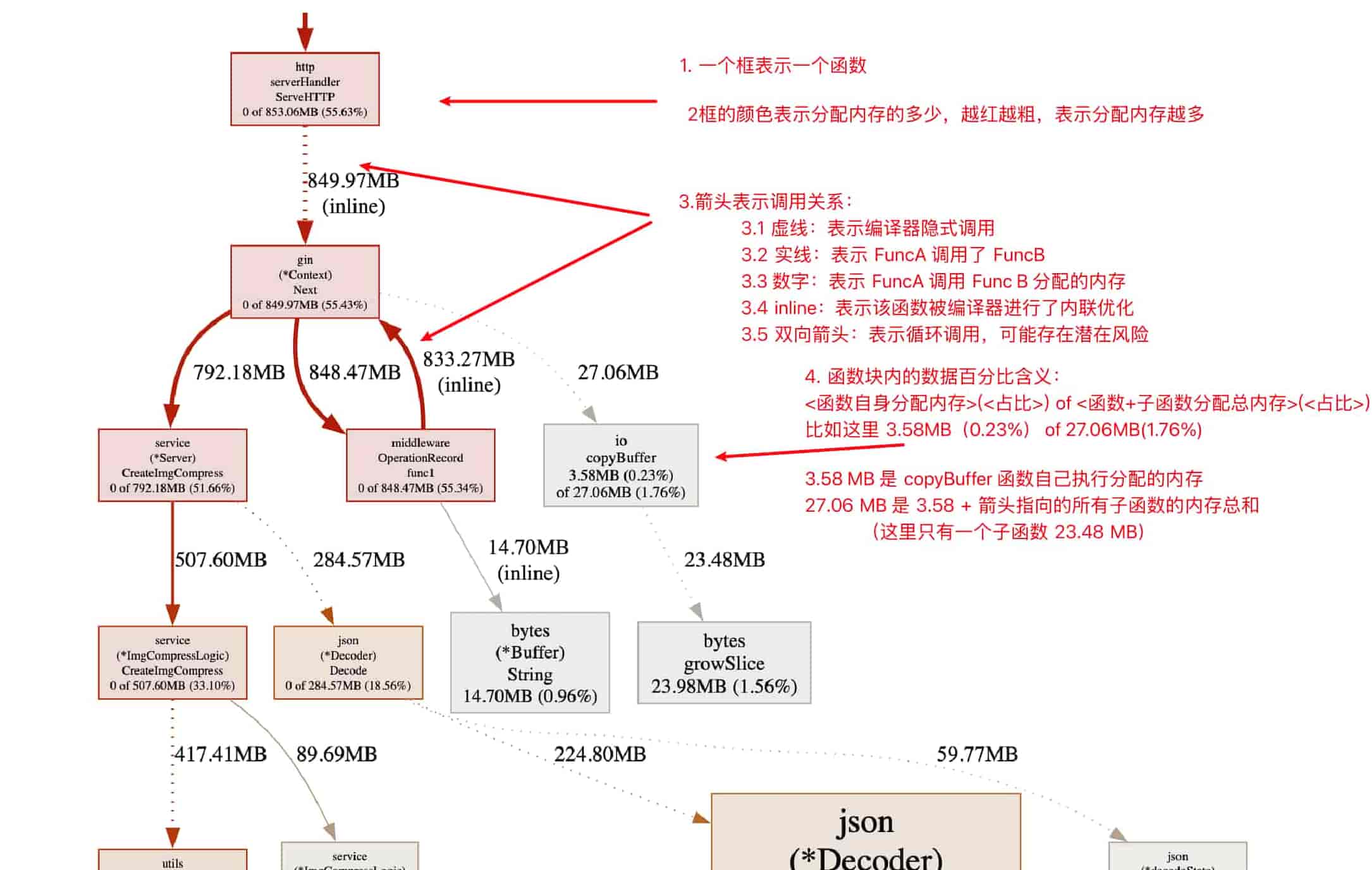
从上面可以分析出:
- OperatuonRecord 存在循环调用,需要确认是否是正常的
- CreateImgCompress:该函数内存分配很多,通过火焰图分析该函数的调用函数的内存分配情况,找到存在问题函数
(三)指标分析
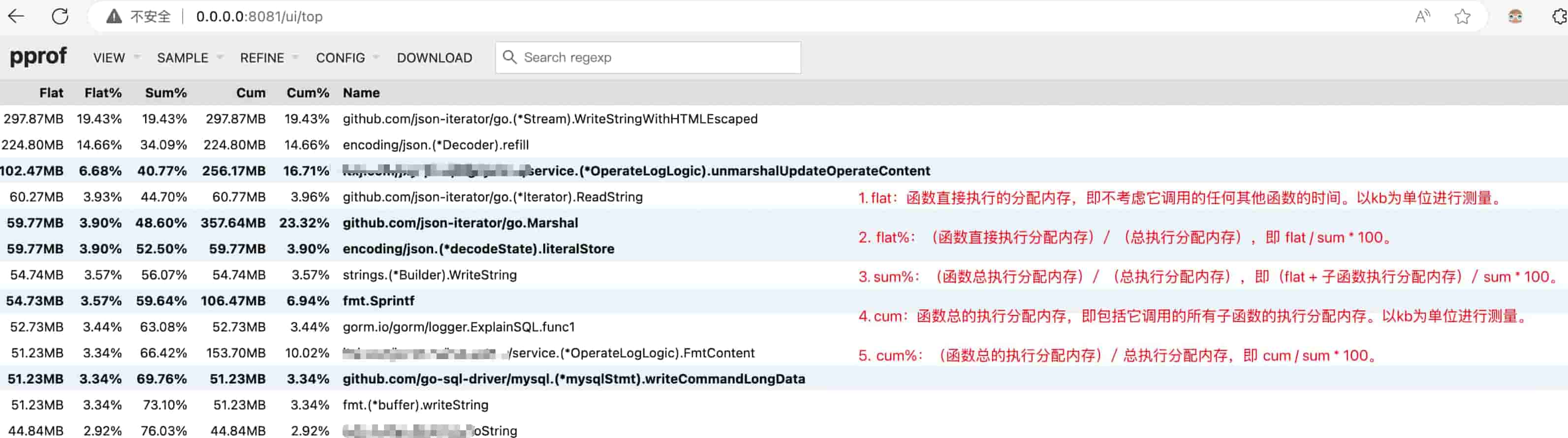
该图为样例图,和上面的火焰图不是同一个采样数据,因此数据可能对不上
- flat:函数直接执行的分配内存,即不考虑它调用的任何其他函数的时间。以kb为单位进行测量。
- flat%:(函数直接执行分配内存)/ (总执行分配内存),即 flat / sum * 100。
- sum%:(函数总执行分配内存)/ (总执行分配内存),即(flat + 子函数执行分配内存)/ sum * 100。
- cum:函数总的执行分配内存,即包括它调用的所有子函数的执行分配内存。以kb为单位进行测量。
- cum%:(函数总的执行分配内存)/ 总执行分配内存,即 cum / sum * 100。
(三)总结
-
查看火焰图:
哪个框又红又粗,就是内存分配最多的函数,通过函数之间的调用链(箭头)快速定位到函数所在的代码, 然后进行优化(见文末【常见优化措施】)
-
查看
top视图:若火焰图不太能定位函数代码实际位置,可以查看 top 视图,会展示问题函数所在的代码文件
六、协程分析
分析进程中协程的运行情况
(一)命令
浏览器直接打开一下地址即可
# 协程的情况(总览)
http://0.0.0.0:30552/debug/pprof/goroutine?debug=1
# 协程的具体阻塞堆栈情况
http://0.0.0.0:30552/debug/pprof/goroutine?debug=1 协程的分析可以直接打开 pporf 服务提供的接口
debug: 表示以纯文本的方式展示,值:1-总览;2-具体堆栈信息
(二)数据分析
协程总览
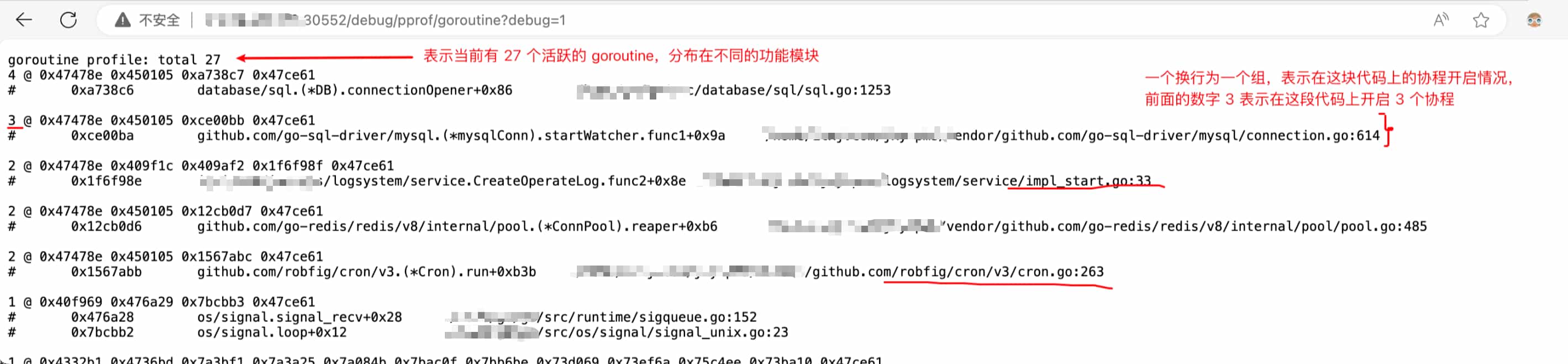
可以看得进程一共有 27 个协程,数量多和少没有绝对好坏,主要看这个数量是否是业务需求所需的
协程具体运行信息
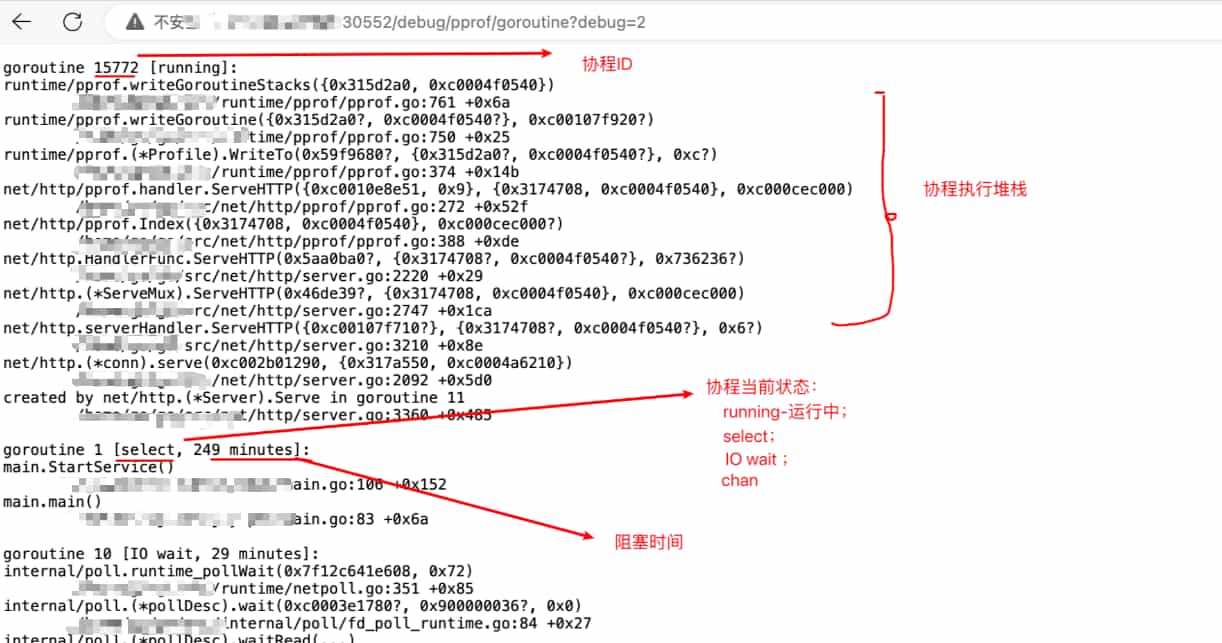
这里会列出所有协程的运行堆栈信息,注意:协程ID不是越大就有问题,主要看这个协程所在堆栈是不是存在阻塞问题
(三)总结
-
1.查看总的协程数量,如果过多,可能存在协程泄漏
-
2.查看协程的运行堆栈信息,看看是不是业务所需的
比如这里就存在一个 trace 的协程,但是我服务并没有这块需求,如下图:
pprof协程泄漏

从这个堆栈看到有个第三方的包开启了这个协程,排查代码发现,程序确实导入这个包,但是这块功能并没有用,因此直接注释掉相应的代码和导包即可
七、锁分析
分析程序锁的竞争使用情况
(一)命令
浏览器直接打开一下地址即可
http://0.0.0.0:30552/debug/pprof/mutex?debug=1锁的分析可以直接打开 pporf 服务提供的接口
(二)数据分析
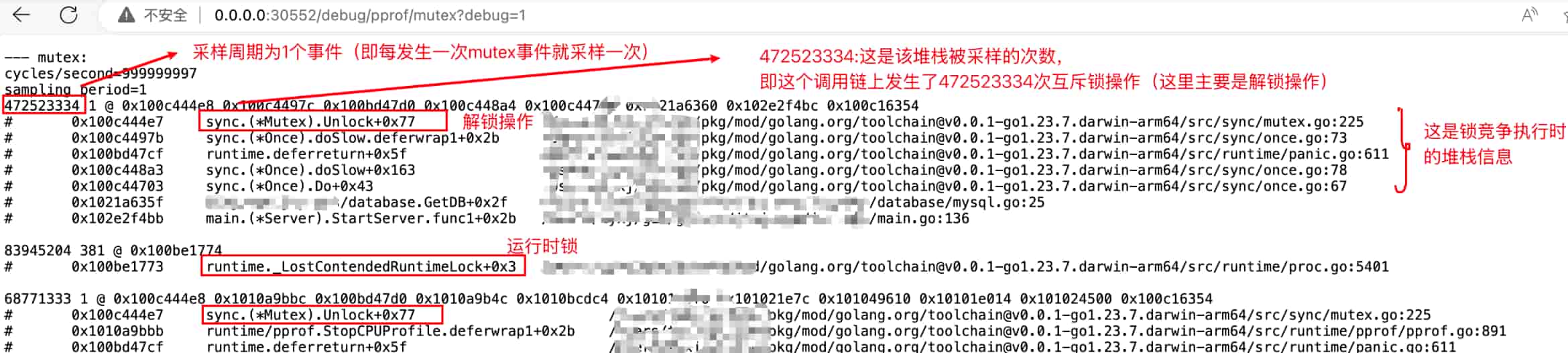
总结
- 从界面上可以看到执行锁的竞争次数最多的堆栈信息,然后看下堆栈是不是你的业务代码,确定代码位置,确实是否需要优化
八、阻塞分析
分析程序阻塞的情况
(一)命令
浏览器直接打开一下地址即可
http://0.0.0.0:30552/debug/pprof/block?debug=1阻塞分析可以直接打开 pporf 服务提供的接口
(二)数据分析
以上就是常见的 pprof 性能指标分析
九、单元测试
除了开启 pprof web 服务采样性能分析,我们还可以使用单元测试,生成 pprof 数据,这在某个函数的性能优化上非常有用
参考代码如下:
func main() {
// --- cpu 分析示例 start---
// 创建cpu分析文件
fc, err := os.Create("./cpu.pprof")
if err != nil {
fmt.Println("create cpu.pprof err:", err.Error())
return
}
defer fc.Close()
err = pprof.StartCPUProfile(fc) // 开始分析cpu
if err == nil {
defer pprof.StopCPUProfile()
}
var count int
for i := 0; i < 10000; i++ {
count++
}
// --- cpu 分析示例 end---
// --- 内存 分析示例 start---
fm, err := os.Create("./memory.pprof")
if err != nil {
fmt.Println("create memory.pprof err:", err.Error())
return
}
defer fm.Close()
err = pprof.WriteHeapProfile(fm) // 开始分析内存
if err != nil {
fmt.Println("write heap pprof err:", err.Error())
return
}
for i := 0; i < 10000; i++ {
count++
}
fmt.Println("do finish......count:", count)
}
// --- 内存 分析示例 end---生成的 pprof 数据文件就可以使用 go tool pprof <pprof 数据文件> 进行分析了,具体分析方法和前面的步骤一致
常见优化措施
1. 字符串拼接性能
这是非常的性能问题,我们都很习惯用 += 进行字符串拼接,但是在大量字符串拼接时性能非常低下 请移步文章:Go语言字符串拼接性能对比与最佳实践 - 深度优化指南
结论:就是使用 strings.Builder
2. 数据库 sql 语句阻塞
一般都是慢查询sql导致,优化下sql语句即可
3. 内存频繁分配
如果你从 pprof 中看到 growSlice ,那大概率是切片频繁进行了内存分配
我们可以通过预分配切片的方式减少内存分配次数
var slice=make([]any,0,cap) // cap 为容量
var m=make(map[string]any,cap) // cap 为容量4. 协程泄漏
从协程的分析中,看到一些本应该关闭但是阻塞的协程堆栈,就可以定位代码,是否有正常关闭协程,可以给协程添加 context 超时机制,避免协程泄漏
5. json 分配内存过多
如果频繁的使用 json.Marshal ,推荐替换 encoding/json —>github.com/json-iterator/go 性能有极大的提升
常见问题
1. 开启 pprof 会影响服务性能吗
肯定是会的,虽然 pprof 对服务性能的影响通常很小,但是高负载或特定分析场景下可能会有一定影响,所以不建议在生产环境长期开启,在需要性能排查时再开启
2. 内存堆栈和内存分配有什么区别作用?
pprof 内存堆栈(heap) 和内存分配(allocs)的区别作用如下
| 维度 | heap (堆内存分析) |
allocs (内存分配分析) |
|---|---|---|
| 观察对象 | 当前存活对象 | 所有分配行为(含已释放对象) |
| 数据来源 | 实时内存堆快照 | 内存分配器事件采样 |
| 时间视角 | 空间维度(当前内存占用) | 时间维度(历史分配总量) |
| 关键指标 | inuse_space/inuse_objects | alloc_space/alloc_objects |
| 最佳适用场景 | 内存泄漏/常驻内存过大 | GC压力/分配热点/频繁短命对象 |
| 分析侧重点 | “谁占着内存不放” | “谁在不断申请内存” |
谁一直在占用内存:用 heap
谁一直在申请内存:用 allocs
3. 如何分析哪些函数占用CPU 耗时比较多?
见步骤【三、CPU 耗时分析】
4. 如何分析哪些函数占用内存比较多?
见步骤【四、内存堆栈分析】
5. 如何分析哪些函数分配内存比较多?
见步骤【五、内存分配分析】
6. 如何排查协程 goroutine 泄漏?
见步骤【六、协程分析】
7. pprof 控制台模式常见命令
go tool pprof 不使用 -http 时,便会进入控制台模式
Fetching profile over HTTP from http://0.0.0.0:30552/debug/pprof/profile
Type: cpu
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 150ms, 83.33% of 180ms total
Showing top 10 nodes out of 143
flat flat% sum% cum cum%
30ms 16.67% 16.67% 40ms 22.22% runtime.lock2
30ms 16.67% 33.33% 30ms 16.67% syscall.Syscall
20ms 11.11% 44.44% 20ms 11.11% runtime.step
10ms 5.56% 50.00% 10ms 5.56% golang.org/x/net/http2.(*Framer).readMetaFrame
10ms 5.56% 55.56% 10ms 5.56% google.golang.org/protobuf/internal/impl.(*enumConverter).PBValueOf-
help
可以获取帮助,最先会列出支持的命令
-
top
按指标大小列出前10个函数,top 5 列出前5个
-
list
可以使用 list 函数名 命令查看具体的函数分析
-
traces
打印所有调用栈,以及调用栈的指标信息
每个
- - - - -隔开的是一个调用栈